

This post is a summary of Matt Stempeck’s presentation at The Impacts of Civic Tech Conference (TICTEC) in Lisbon, Portugal, on April 18, 2018, which he developed in close consultation with Micah Sifry, and is part of the ongoing work they are doing developing the Civic Tech Field Guide.
If you work in civic tech, you’ve probably read a lot of impact studies and annual reports. What we’d like to share today are some of the issues that make the kind of rigorous impact measurement research efforts of civic tech projects that TICTEC promotes very difficult to conduct.
Though gleaned from years of experience, the following list includes some opinions. They are issues that have come up repeatedly and haven’t been adequately addressed. These problems affect impact measurement efforts by independent researchers, as well as organizational staff and funders looking to invest wisely.
- We’re all using different metrics
- Sharing is irregular
- Most projects don’t reach most people
- Different constituencies want different impacts
- We don’t evaluate relative to investment made
- We don’t evaluate relative to the macro environment
- Quantitative metrics can miss the objective
- Case studies are too often biased
- Causality is hard to prove in social environments
- Our externalities may eat us all
But first, a few lines on how impact measurement can work, in an ideal world:
We start with the outcomes our group or platform is looking to achieve—why we exist in the first place.
Working backwards, we identify metrics or stories or other accounts that can serve as reliable proxies and milestones, that offer evidence that we’re making progress toward our outcomes.
And then, the sweet spot: when you (or ideally, someone else) does the research that actually proves or disproves a causal link between people’s usage of that platform or technology and that effect we’ve observed.
For example, the Center for Humanitarian Data‘s mission is to make crisis data more immediately available to crisis responders. So they set these 3 measurements as proxies to measure progress towards their long-term goal:
- Increase the speed of data from collection to publication
- Increase the number and quality of the Center’s connections in the humanitarian space
- Increase the use of the Humanitarian Data Exchange that underlies their work
This causal link between the specific work we’ve done and a general outcome is hard to establish. Most groups don’t have in-house researchers trained in defensible methodologies, or the resources to hire them. Research requires resources, which is why you often see groups do impact assessment work when funders provide dedicated resources to conduct that research, and stop when that funding is depleted. Beyond the availability of resources, there’s also a lot of pressure to take credit for forward progress on an issue without really interrogating its origin.
So let’s get into it.
1. WE’RE ALL USING DIFFERENT METRICS
The first reason that systematic measurement of the impact of civic tech is so difficult is there’s a lot of variation in the types of metrics groups collect and share. Even some groups working on the same issues as each other point to completely different metrics to show their impact. Groups might even build a brand around a set of impact metrics as the path to progress (see Upworthy’s Attention Minutes). Despite all the metrics involved, impact measurement is a pretty subjective game.
In interviews with civic tech groups like Code for America, Living Cities, and Emerson Engagement Lab’s Community Planit, Network Impact found that even within the same civic tech projects, groups collect and measure different metrics at different stages of product growth.
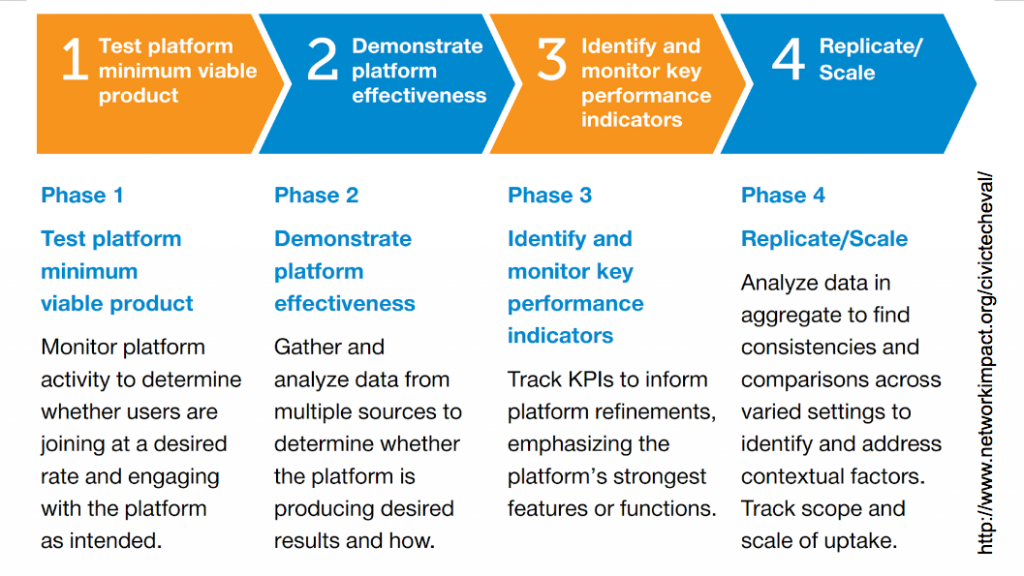
If you’re familiar with the lean startup methodology, this finding and graphic hew nicely to it.
In the design and early launch stages, you’re very focused on metrics involving user recruitment in order to find the demand for what you’ve built, and get people using it.
Assuming you’ve done that, and you have a critical mass of users, the next phase is to see what they do with the tool. When people use your civic tech tool, is it producing the intended result? Over time, you ideally see enough usage to have interesting data to detect user patterns. This should inform where future development resources go.
2. SHARING IS IRREGULAR
Not only do the same groups prioritize different impact measurements over time, they might also be more or less transparent at various points in the organization’s life. Sometimes groups will share a lot of valuable impact information, like when they’re seeking press coverage and early funding, and then they might stop sharing entirely, when they no longer have a strong need to. Groups might happily share their impact numbers when those numbers are going up, and then become silent when the trends are less exciting. Which is understandable, but a shame, because that is exactly the period from which we need to learn.
Irregular sharing of impact is tough on our ability to conduct meaningful research. To do a longitudinal analysis on the impacts of civic tech, we need to have a sense of a variable over a set period of time, with regular and reliable measurements. In civic tech, what we might get instead is a report that was published thanks to a specific grant, and then nothing for a few years, and then a pivot to an entirely new evaluation method. Again, this is understandable behavior for those working with finite resources, but hampers impact assessment in our field.
In my talk, I presented three examples of impact-sharing frequency. I argue it’s rare for groups to provide a continuous and consistent record of impact over many years. Here are three approaches:
- Code for America had a clear URL naming convention for beautiful annual reports: 2011.codeforamerica.org, 2012, 2013, and 2014. But after searching with their site’s search engine, their Github repos, and Google, I wasn’t able to find impact or annual reports for 2015 – 2017 online. Someone at CfA helpfully followed up and sent the link to their 2017 report, and suggested that this information would be easier to find on their site in the near future.
- With some of the bigger platforms like Change.org, and Care2, we see the Victory Stories approach. We’re given evergreen marketing pages that focus on select wins rather than actual impact assessment (other than some very large top-line statistics about the massive size of their platforms). We are not given the data to consider the efficacy of using such petition tools. How many petitions failed relative to the gallery of victories we’re browsing?
- One group to celebrate for both its depth and regularity of public impact reporting is DoSomething.org. Their Dashboards reports are published quarterly, or at least bi-annually, and include metrics and stories related to their campaigns for that period, as well as indicators of overall organizational health.
3. MOST PROJECTS DON’T REACH MOST PEOPLE
Reporting frequency aside, we do have one common impact metric in civic tech, and that’s scale. How many people are you reaching with your product or service? This one’s easier because if it’s a big number, we’ll probably hear about it. Juggernauts like Avaaz and Care2 put it right on their homepages: 42 million email members. 8 billion signatures. All the world’s countries and territories.
Of course, we don’t hear about user numbers from most civic tech products. Maybe that’s because it’s proprietary information for private, for-profit startups. It can also be because it’s often not a big number. Micah Sifry will go into greater depth on this topic in a piece on learning from failures in civic tech, but the majority of the civic tech tools for which we have numbers have under 20,000 users.
When we talk about scale, I always have my eye on relative share of global populations, because we’re usually talking about serving the public at large with these tools. If we claim our work serves the public interest, can we at least show that we’re serving the public? How does our traction compare with more universal human experiences like popular music, food, and sports?
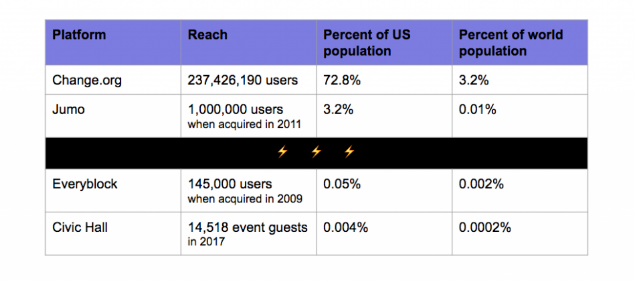
Not well! Even well-funded projects like Jumo and Everyblock only reached a tiny fraction of Americans. The most famous examples in our field reach a tiny, tiny portion of the U.S. and world. (This is one reason I’m still bullish on embedding civic features inside of mainstream tech products.)
And then there is, of course, the problem that reaching a large number of users does not inherently equal ‘impact’. Our understanding of web technology is fundamentally colored by the investment model that funded so much of it: venture capitalism. And venture capitalists have demanded large numbers of users to justify large investments (sometimes larger than the fundraising company actually wants to take). But small tech can have large impact, especially in a civic context. Stefan Baack, a researcher at the Alexander von Humboldt Institute for Internet and Society in Berlin, writes:
Scale of direct use can be a poor measure of impact. Often, what matters in terms of impact is how relatively small groups are using civic tech applications: e.g. minority groups that the civic tech application aims to support, or a relatively small but impactful elite (e.g. professional journalists, community organizers, NGOs etc.).
4. DIFFERENT CONSTITUENCIES WANT TO SEE DIFFERENT IMPACTS
If you’ve ever led an organization, you already know this: you have to report to different constituencies, and they often want different things. When it comes to impact measurement, that means that different constituencies may want to see completely different results before they’ll consider your work effective.



Your actual theory of change might dictate: more sponsors of this legislation will increase the chance it passes, and that will achieve our goal. But funders might instead require you to score and track media appearances. And the public, your members, might expect you to offer compelling social media updates and respond to the news cycle. You’ll have to execute some of each, and optimizing for one mode of impact might depress your impact in another.
One organization was keen on showing their impact via the number of software developers who had requested keys to their APIs, and how many calls for information they then made. Their funders wanted to see them making progress in winning media coverage. If you were building tech at an organization like that, you’d build one product to optimize for increased API usage, and something else entirely to achieve greater media coverage.
5. WE DON’T EVALUATE RELATIVE TO INVESTMENT MADE

Even when we adequately measure outcomes, we often fail to do so in relation to the resources that were invested in the work. This has consequences for our space.
Resources might mean grant money. Resources can also take the form of public attention, especially if one group dominates the public’s finite attention span for an issue.
Let’s take Jumo. Jumo was going to be THE single, central platform for nonprofits, except for all the other single, central platforms for nonprofits. With Jumo, the inputs included $3.5 million from funders, a high profile launch, and the individual contributions of thousands of nonprofits and a million people creating profiles.
In under a year, Jumo folded. Its value at that point was appraised at $62,221, and it was sold off to GOOD for that much and 5 laptops. In addition to the $3.5M invested, all of the community effort went nowhere. Jumo’s answer to those wasted efforts was open-sourcing the code and suggesting that “the community” would keep the site up and running. This may surprise you, but that did not happen.
Now let’s look at the inverse: groups that continuously produce work well beyond the inputs they’ve received:
- Govtrack.us serves 7-10M visitors a year with information about U.S. legislation and the federal government, and receives zero dollars from outside groups.
- Chris Messina migrated the hashtag over from IRC to Twitter, a social practice innovation that took him zero resources, and took Twitter relatively few resources to support with code. This conversational practice has generated untold benefits for this century’s digital-first campaigns, from #metoo to #blacklivesmatter.
- The 92nd St Y started Giving Tuesday, and has spent pennies on the dollar marketing the program relative to the hundreds of millions of dollars the day now generates for social causes and nonprofits.
Funders might be willing to invest in open source brands like #GivingTuesday if we kept better track of impact relative to inputs.
6. WE DON’T EVALUATE RELATIVE TO THE MACRO ENVIRONMENT

Our perception of a group’s impact is inextricably tied to the macro environment in which they operate. We inadvertently penalize groups working in very difficult contexts, and we tend to ascribe prowess to groups that may have benefited from fortunate timing.
Countable is one of many, many civic tech tools that allow you to contact your representative and weigh in on legislation. And they were wise to build a user friendly, mobile-first product. But in considering their success, should we also acknowledge the role of timing, and Countable’s relative position when Donald Trump was elected, and suddenly millions of Americans were newly eager to engage in politics? The point is not to denigrate success stories like Countable, but to keep in mind that we should remember to sustain the groups working in difficult environments, even knowing that their impact is going to be much harder to perceive as a result.
7. QUANTITATIVE METRICS CAN MISS THE OBJECTIVE
It’s really nice to work with real numbers. If you’ve ever worked at an organization that’s a) been around a long time and b) used Key Performance Indicators to evaluate employees, you’ve likely come across KPI fatigue. That’s because the KPIs we set might not keep up with the actual conditions out in the world, and yet we keep measuring impact (and employee contributions) by stale proxies.
Quantitative impact metrics can miss the overall point of the work. In the right context, we might have crazy great success on key performance indicators and see it not matter whatsoever.
Here’s a personal fail informed by reliance on quantitative metrics. In 2016, I worked on the digital team for the Hillary Clinton campaign. We broke all sorts of campaign records for measurable impact metrics. We built a platform on which volunteers sent 35 million targeted, actionable text messages to key voters. We won the endorsement of 57 of the top newspapers in the country, while our opponent gained 2 (one of which was owned by Sheldon Adelson). Which is unheard of. But as you already know, we failed our one objective, the one reason for our organization to exist, even though all of our empirical data showed us winning. Organizers from vital Electoral College states like Michigan asked for help, and were told that the conditions they were experiencing on the ground were anecdotal. Specific quantitative metrics can easily miss the forest for the trees.
And then there’s the ‘aura of objectivity’ that many of us attribute to quantitative metrics. Sally Engle Merry writes in The Seductions of Quantification, “numbers convey an aura of objective truth and scientific authority despite the extensive interpretive work that goes into their construction.”
8. CASE STUDIES ARE TOO OFTEN BIASED

As I read a collection of impact reports and reflected on what works, I gravitated towards strong narratives, because they can embed the true drivers of an outcome. Jonathan Fox brought this up at TICTEC as well, discussing ‘causal stories’. Nicole Anand at The Engine Room refers to their work helping other groups win as “unpacking the action chain to impact”. We might think of impact narratives as an action chain, too.
Years ago, the investigative journalism nonprofit ProPublica wrote a great whitepaper (“Nonprofit Journalism: Issues Around Impact“) on how they think about their impact. It specifically discusses the tension between a deeper, qualitative scoring of their work and what would be left out if you simply tallied the number of times their journalism likely produced societal changes. I trust their qualitative findings, as well as the tally, because I trust ProPublica, but as they point out, qualitative impact reporting can require a bit of trust on the part of the reader.
Depending on the report, there can be serious issues with accuracy and bias in case study reporting. These reports are often commissioned by the funder of the group itself, or written by peers with social ties to the subjects, or the group itself wrote the report based on a sample of their most active and enthusiastic users. Even academic articles about emerging civic technologies are often written by their champions inside of academia.
That’s all fine if we just want to increase awareness of a group’s work, but it’s not helpful for getting us to the heart of TICTEC, which is knowing empirically if we’re having a relatively positive impact on the goals we state. I’d personally like to see more truly independent case study authors and more balanced reporting. Case studies need to include more recognition of setbacks and failure, if we’re to learn from them.
9. CAUSALITY IS HARD TO PROVE IN SOCIAL ENVIRONMENTS

Causality is hard to prove in a societal context. That’s not to say there haven’t been good studies. Rebecca Rumbul, Head of Research at MySociety (the conveners of TICTEC), has led rigorous studies on citizen reporting tools including MySociety’s own, and they were brave enough to publish the sometimes discouraging results. The civic engagement teams at Facebook and Google have conducted research, including strong control / variable treatments of their civic engagement tools, and shared results.
But causal impact research is not always straightforward. For example, the Sunlight Foundation has received millions in funding over the years. It also identified that the U.S. federal government’s own expenditure tracking was off by $1,300,000,000,000. That discovery helped lead, some argue directly, to the passage of the DATA Act, which itself standardized U.S. government spending reporting and will prevent unprovable but certainly large amounts of fraud.
10. OUR EXTERNALITIES MAY EAT US ALL

And lastly, here’s something to reflect on that came up several times at TICTEC: The unintended consequences of our work could end up more impactful than the work itself. Sit with that for a minute.
One of the core conceits of building technology is that other people will use it as we intended. Tom Steinberg talks about 19th century medicine, where most of a century of progress was lost to the idea that we were helping others when the interventions were often just causing further harm. A more recent example: Facebook’s grand mission to “make the world more open and connected” sounded innocuous enough for a corporation. Fast forward to 2 billion users, and you get unfortunate, unintended consequences like when your find-friends tool, designed to increase user engagement and retention, is found to be leveraging network science to introduce would-be terrorists to one another.
Do we know, or even consider, the long-term ramifications of our work? Does transparency of government bureaucracy produce more cynicism than engagement? Does publishing property data online in a distressed city like Detroit empower land speculators rather than residents? Does connecting the whole world to one another produce an exploitable fear of the other, rather than a vaguely defined ‘community’? What are the byproducts of our work on a historic timeline? The point, is we don’t really know, and we need to at least consider them.
Reaching a better understanding of impact, how to adequately measure it, and knowing which products and services are really shining, are all reasons that we’re expanding upon the Civic Tech Field Guide. We started this collection with just an inventory, and now we’re building out more ways to collect data on each civic tech project, including impact reporting, so that we can begin to learn more about our field in aggregate.
We’d love to invite you to contribute your research and your impact evaluations to the guide, either directly in the Impact Measurement section (Column BK), by getting in touch, or sharing examples with this form.
All this said, there’s an entire practice of measurement and assessment in adjacent fields like the humanitarian sector. Which existing practices should we be adapting?